

О проекте
Современные большие языковые модели (такие как ChatGPT, Llama, YandexGPT, GigaChat) активно развиваются и нуждаются в честном сравнении и независимой оценке. Единого стандарта для оценки не существует, и поэтому модели невозможно честно сравнивать, так как замеры проводятся в разрозненных экспериментальных постановках (разные данные для оценки, способы замера). Открытость и прозрачность процедуры — это ключевая проблема оценивания, в том числе потому, что модели как правило оцениваются разработчиками, заинтересованными в том, чтобы их модели получали высокие оценки. Мы представляем русскоязычный индустриальный бенчмарк для комплексной проверки крупных языковых моделей в отраслях сельского хозяйства и медицины и здравоохранения. На сайте бенчмарка есть рейтинг моделей по качеству решения фиксированного набора задач, составленных экспертами, со стандартизированными конфигурациями промптов и параметров. Проект поддерживает Альянс ИИ, ведущие индустриальные игроки и академические партнеры, которые занимаются исследованием языковых моделей.

Мы предлагаем методологию тестирования, основанную на тестах для сильного ИИ:
Она включает широкий спектр сложных тестов, ориентированных на критически важные профессиональные сферы, такие как сельское хозяйство и медицина. Все задачи данного сета были созданы ведущими экспертами в областях сельского хозяйства и медицины, отредактированны профессиональными редакторами, затем вручную перепроверены по очереди тремя экспертами.
Как устроены промпты для задач?
Для каждой задачи эксперты вручную составили несколько разных универсальных промптов-инструкций, независимо от моделей, с четко обозначенным требованием по формату вывода ответа. Эти промпты равномерно распределены между всеми вопросами в задаче по принципу "один вопрос — один промпт". Такой формат позволяет получать усредненную оценку по разным промптам, и все модели оказываются в равных условиях: промпты не "подсуживают" конкретным моделям. Из этих соображений инструкции нельзя менять при замерах моделей, так же как и параметры генерации и few-shot примеры.
Как устроен замер?
Кодовая база для оценки на бенчмарке MERA разработана на основе международного фреймворка LM Evaluation Harness, который позволяет оценивать модель в генеративном и log-likelihood формате.
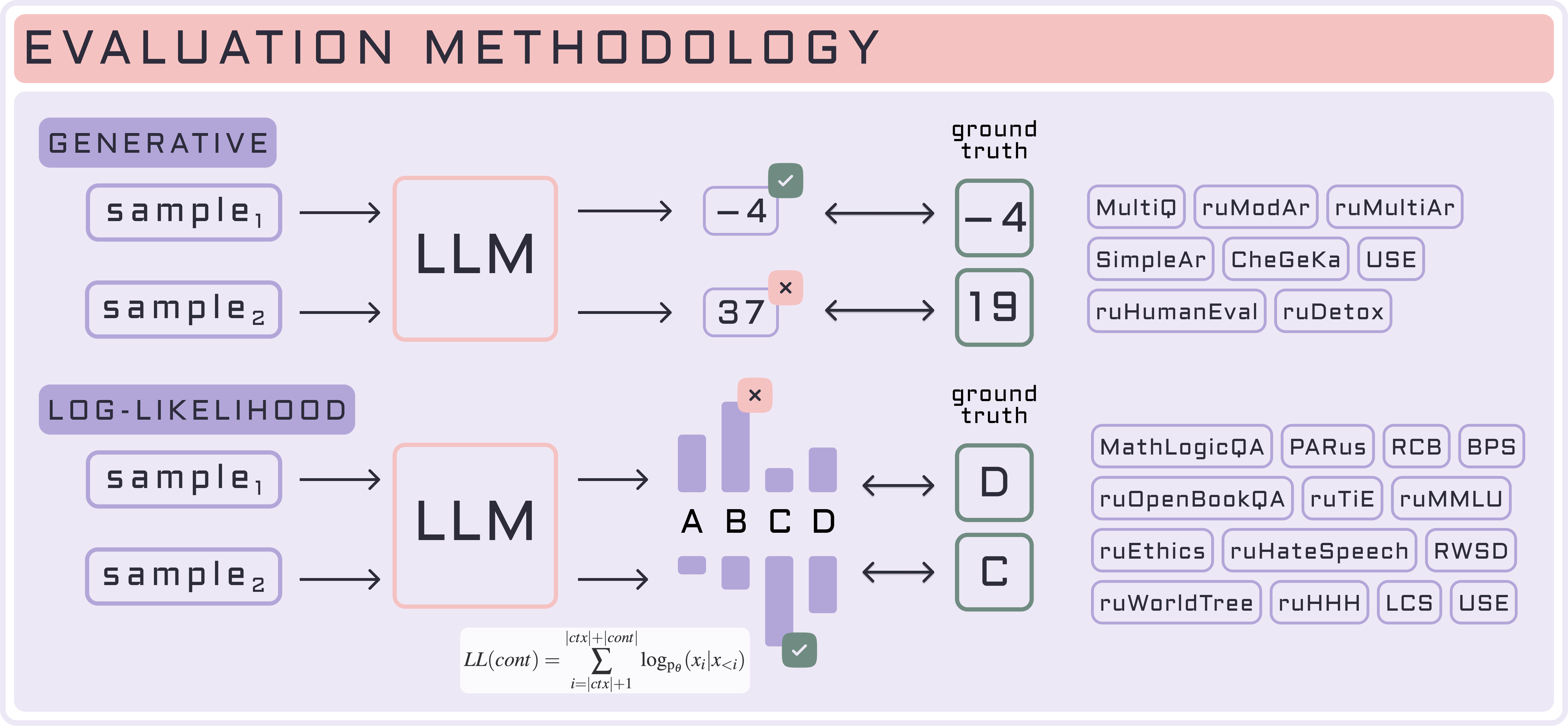
| Генеративная оценка | Log-likelihood оценка |
|---|---|
| Не требует доступа к логитам, подходит для любой модели, которая умеет генерировать текст. | Нельзя оценивать модели API, так как они как правило не возвращают логиты, на основе которых построена log-likelihood оценка. |
| Требуется постобработка ответа (универсальной эвристики нет, human side-by-side (SBS) и LLM-as-a-Judge / специальные парсеры). | Не требуется постобработка ответа модели, так как ответ — фиксированная буква или число. |
| Маленькие по размеру модели генерируют нерелевантные ответы. | Позволяет оценивать вероятность получить конкретные ответы от языковой модели. |
| Рекомендуем запускать инструктивные модели (SFT-like) и API только в генеративном сетапе. | Лучше подходит для замеров претрейн моделей и маленьких моделей. |
Полезные ссылки
 Репозиторий:
Репозиторий:
 Публикация:
Публикация:
 HF datasets:
HF datasets:
 Чат техподдержки:
Чат техподдержки:
 FAQ
FAQ